ElasticSearch - Preventing Split Brain With a Cluster!
Elasticsearch - Brain Cluster !
After reading this about article about elastic search cluster --Split - brain problem I wanted to be careful about setting an elastic search cluster.I have to setup a 3 node cluster of elastic search. After reading a few articles about it, it comes down to how the cluster will be used mostly. Here are some of the questions that i asked when setting the cluster up. I hope that this can be a good starting point for anybody setting up elastic search cluster.
1. How many nodes are you going to use for the cluster ?
We only have 3 physical servers that is why i decided to use a 3 node cluster.
Here are the settings that i used
Gave the cluster a name [cluster.name: brain] - brain cluster
Gave each node a name [node.name: "brain_1"']
[node.name: "brain_2"']
[node.name: "brain_3"']
a master node [node.master: true]
a data node [node.data: true]
http enabled
I decided all nodes to be master and data node because I only have 3 servers. If I have more 10-12 servers I might have employed a different strategy. I would have done at least 3 master nodes. 3-8 data nodes and 3-4 exclusive search nodes (not a master node nor a data node)
2. Are you going to be doing more searching or indexing ? How often are you going to index ?
- This will help determine if a tribal node is going to be good for you because you might encounter some issues indexing a tribal node specially when your index names are the same across clusters. Here is a link that explains how Tribe node works for elasticsearch
Tribe Node Elasticsearch
3. Do you want the nodes to auto discover each other ?
Elastic search uses zen discovery to automatically cluster any elastic search instances running in the same network. I have to deal with a head splitting issue while indexing but as it turns out another developer is running an elastic search instance using the default settings and our instances automatically clustered together.
To turn off multicast discovery set this configuration attribute to false
[discovery.zen.ping.multicast.enabled: false]
and if you want your instance to just try and cluster with certain servers you can define this attribute
discovery.zen.ping.unicast.hosts: ["<hostname>:<port>"] - where
After going through this exercise I have my clusters working. I installed marvel and wikipedia river on all my instances
bin/plugin -install elasticsearch/marvel/latest
bin/plugin -install elasticsearch/elasticsearch-river-wikipedia/2.0.0
After installing the river- I have to run this in Sense against one of the master nodes.
Start pulling data to a new my_wikipedia_river index
PUT /_river/my_wikipedia_river/_meta
{
"type" : "wikipedia"
}
Search it
GET /my_wikipedia_river/_search
POST /my_wikipedia_river/_search
{
"query": {
"term": {
"text": "computer"
}
}
}
Stop pulling data
DELETE /_river/my_wikipedia_river/
This was so easy to setup.
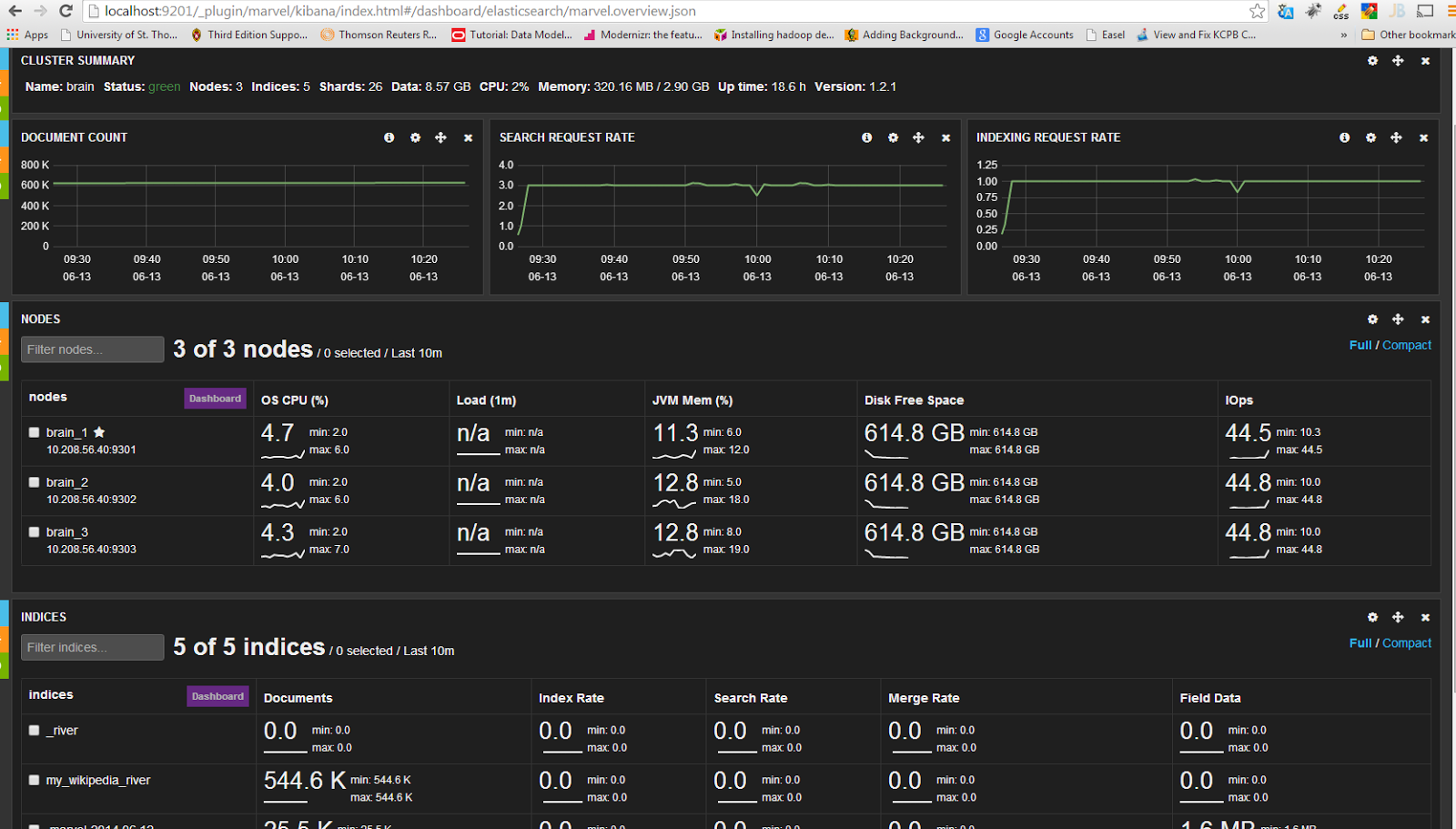
Here is a screen capture of marvel after setting all up. Everything is green!

Comments