Hadoop - a Big Data Sneak Peek (part 2)
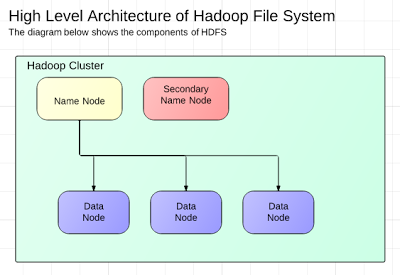
Here is the next installment for Hadoop. I hope this gives you an idea of what HDFS and MapReduce in Hadoop is. Please leave a comment if you find this useful. HDFS Architecture The diagram below shows the main components for the Hadoop File System (HDFS). Name Node - This is the central piece of HDFS. The Name Node tracks all the file system's metadata (e.g. directory tree of all files, where the file is kept in the cluster). It does not store the data itself. The Name Node is the SPOF (Single Point of Failure in HDFS). Here is a link to a more detailed definition -> NameNode Secondary Name Node - optional component of the HDFS. Creates checkpoints of the namespaces Data Node - Stores data in large blocks in the filesystem. Reports the blocks of data it holds to the Name Node. MapReduce MapReduce is a programming model on a distributed processing platform that is scalable. It is actually as three step process. 1. Map - this steps creates a map (key-val...